セグメンテーションとは、画像や動画の各画素を、特定のクラスに分類する技術です。例えば、画像の中の人を検出したり、動画の中の車を検出したりするために使用されます。
今回は「セグメンテーション」をJetson Nano で動かしてみたのでそのやり方を簡単にまとめました。
サンプルプログラムを動かす
サンプルプログラムが正常に動作するかを確認します。
ターミナルで以下のコマンドを実行して必要なソフトをインストールしていきます。
$ cd ~
$ sudo apt-get update
$ sudo apt-get install git cmake libpython3-dev python3-numpy今回使用するプログラムをGitHubからクローンします。
$ git clone --recursive https://github.com/dusty-nv/jetson-inferenceクローンしたファイルをビルドしていきます。以下のコマンドを順番に実行してください。
$ cd jetson-inference
$ mkdir build
$ cd build
$ cmake ../
$ make -j$(nproc)
$ sudo make install
$ sudo ldconfigビルドが終わったら実際に動かしてみます。ここからは、ターミナルを2つ使って作業していきます。
1つ目のターミナルに以下のコマンドを入力します。
$ python3
>>> import jetson.inference
>>> import jetson.utils2つめのターミナルにうつります。
まず、サンプルプログラムのあるディレクトリに移動します。
$ cd ~/jetson-inference/python/examples 移動できたらサンプルプログラムを実行します。この時、カメラが必要になるので接続しておいてください。
$ python3 segnet.py /dev/video0 --width=640 --height=480こうするとウインドウが立ち上がり、セグメントで人をトラッキングしてくれます。
自分でモデルデータを作ってみる
サンプルプログラムが動いたので次は自分で作ったモデルデータを使って動かしてみます。
ここからはパソコンで作業していきます。
パソコンにリポジトリをクローンします。以下のサイトがクローンするリポジトリです。
クローンコマンドを入力します。
$ git clone https://github.com/Onixaz/pytorch-segmentationPytorchをインストールします。
$ conda install pytorch==1.1.0 torchvision==0.3.0 cudatoolkit=10.0 -c pytorch「onnx」と「pycocotools」もインストールしておきます。
$ conda install onnx pycocotoolsラベリングするソフトもインストールします。今回使うラベリングソフトは「Labelme」というものを使用します。
以下のコマンドを実行してインストールしてください。
$ pip3 install pyqt5 labelmeこれで準備完了です。
データ収集
トレーニングする前にデータを収集する必要があります。その準備をしていきます。
データ収集
まず、トレーニングするための画像データを収集する必要があります。今回はすこん部のぬいぐるみをモデルとしてデータを収集していきます。
Webカメラなどを使って対象の画像データを撮影していきます。枚数が多いほど精度が上がります。150枚~1500枚ぐらいが理想です。
Collision Avoidance の Data Collection をもとに作ったプログラムを使ってデータ収集すると効率化できます。
私はJetson Nanoを使って撮影をしました。JupyterLabにアクセスし、データ収集プログラムを起動します。
あとはプログラムを実行していき撮影ボタンを押すことで撮影できます。
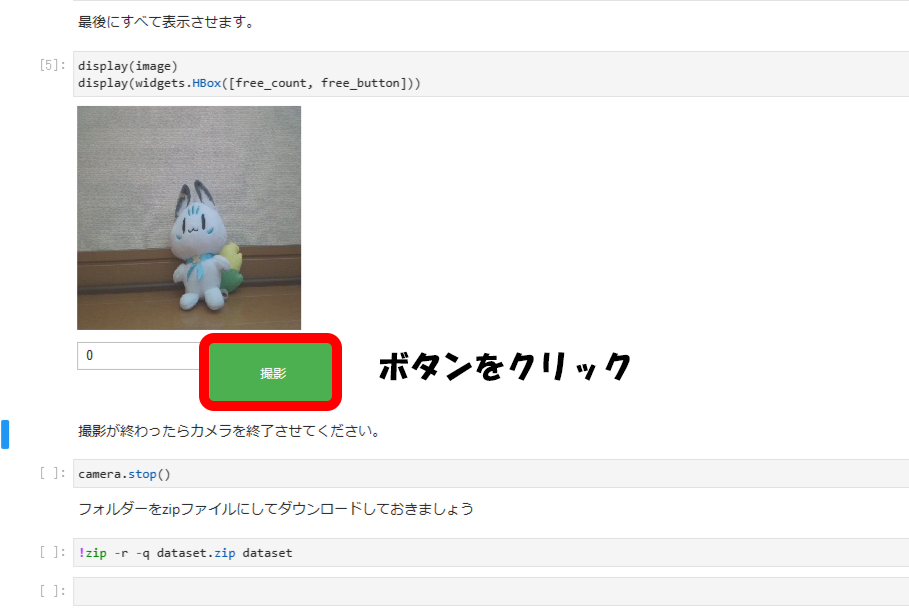
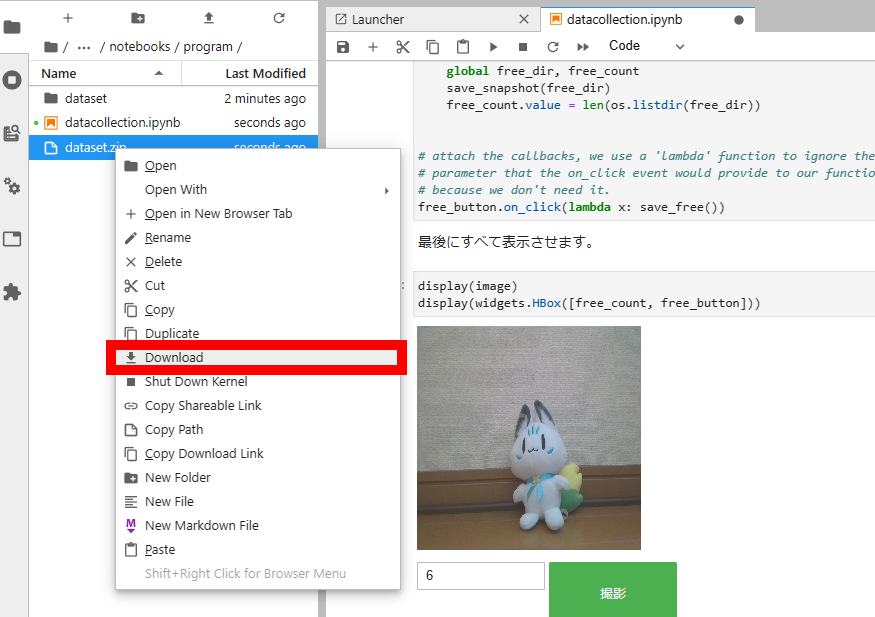
撮影が終わったら最後までプログラムを実行します。そしてできたzipファイルをダウンロードします。ダウンロードは、zipファイルを選択し、右クリック→Downloadの順にクリックするとダウンロードできます。
ラベリング
撮影した画像をラベリングしていきます。この作業は対象をボーンで囲い、それにラベルを付ける作業です。
クラスを決めます。フォルダーを作り、その中に「classes.txt」というテキストファイルを作ります。
テキストファイルにクラス名を入力していきます。以下が例となります。
background
sukonbuそして、視覚化するために使用するRGB値を指定します。同じフォルダーの中に「class.txt」を作成します。そしてRGB値を入力します。
0 0 0
255 0 0JupyterLabからダウンロードした画像ファイルもフォルダーにコピーします。
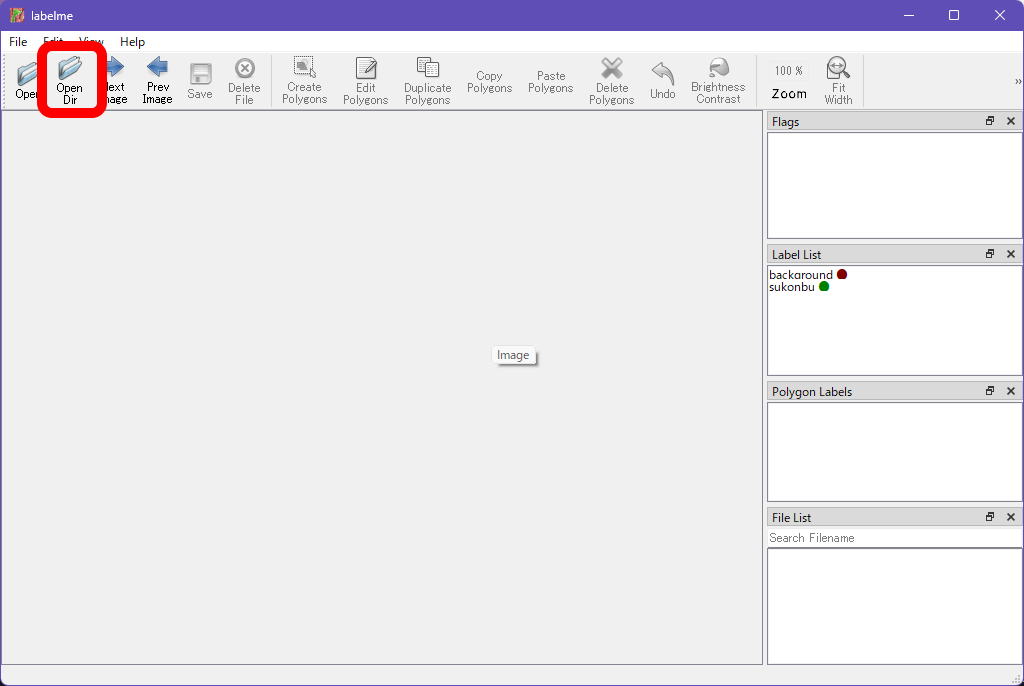
Labelmeを起動します。classes.txtやclass.txtを作ったフォルダーで以下のコマンドを実行してください。
$ labelme --labels classes.txt起動したら画像データを読み込みます。「Open Dir」をクリックして、先ほど作ったフォルダーを選択します。
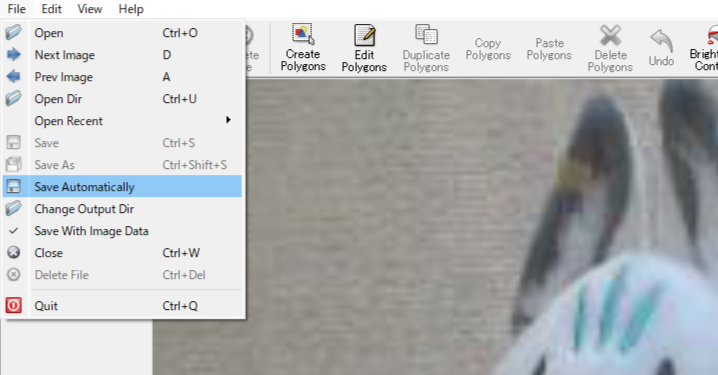
画像を読み込んだら左上のFileから「Save Automatically」をクリックします。これで自動でセーブをしてくれます。
あとはオブジェクトをポリゴンで囲むだけです。

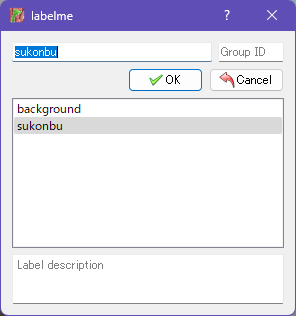
囲んだ後はラベルを選択してOKをクリックします。
保存すると画像であるjpgファイルとjsonファイルができると思います。
できたものをフォルダーごとpytorch-segmentationにコピーします。
※フォルダー名は「sukonbu」です。
(base) remylog@remylog-desktop:~/pytorch-segmentation$ ls
README.md labelme2voc.py onnx_export.py requirements.txt sukonbu transforms.py
datasets models onnx_validate.py split_custom.py train.py utils.pyこれらのファイルをpngイメージマスクに変換します。以下のコマンドを実行してください。
$ python3 labelme2voc.py sukonbu output/folder --labels sukonbu/classes.txt --noviz
データをトレーニング用と検証用に分割します。
$ python3 split_custom.py --masks="output/folder/SegmentationClass" --images="output/folder/JPEGImages" --output="output/dir"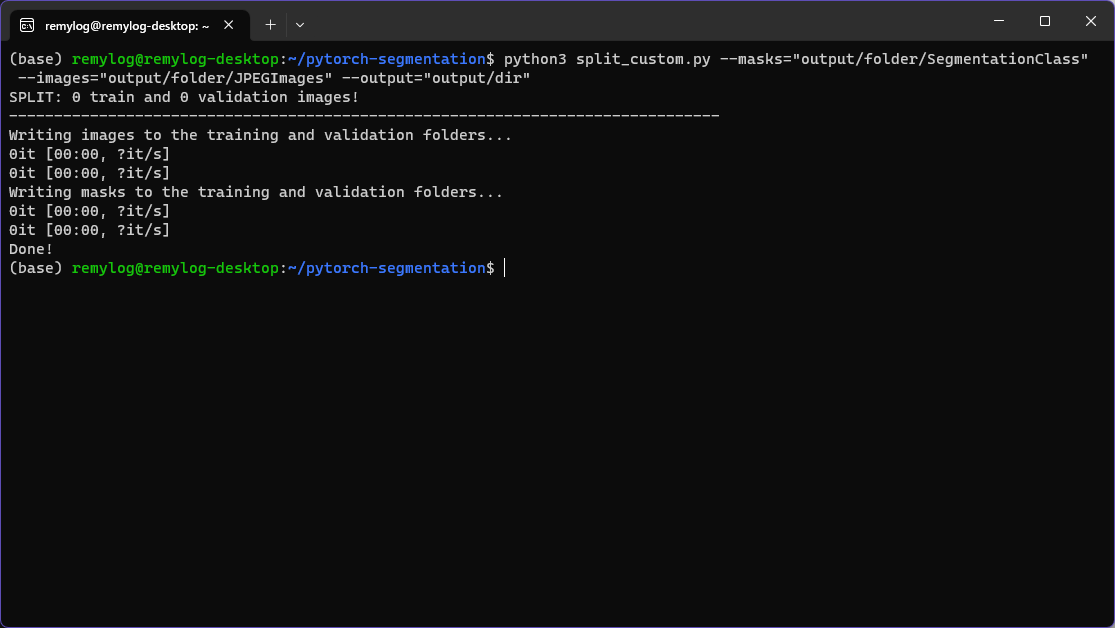
トレーニング
ここからはモデルデータをトレーニングしていきます。以下のコマンドを入力してトレーニングを開始してください。
以下のコマンドを実行したときに
ModuleNotFoundError: No module named ‘モデルの名前’
が表示されることがあります。この時の解決方法として検索欄に
conda モデル名
などで調べるとインストール方法が記載されているサイトがあるのでそれを見てインストールしてください。
$ python3 train.py output/dir --dataset=custom
モデルのデプロイ
モデルをデプロイします。以下のコマンドを実行するだけでデプロイできます。
$ python3 onnx_export.py
データをJetson Nanoにコピーします。コピーするファイルは以下のリストです。
- fcn_resnet18.onnx
- classes.txt
- colors.txt
これらのファイルをJetson Nanoのjetson-inference/python/examples ディレクトリにコピーしてください。
動作確認
最後に動作確認をします。
まず、ディレクトリ「jetson-inference/python/examples 」に移動します。
そして、以下のコマンドを実行するだけで動作すると思います。
$ python3 segnet.py /dev/video0 --model=fcn_resnet18.onnx --width=640 --height=480 --labels=classes.txt --colors=colors.txt --input_blob="input_0" --output_blob="output_0"成功すると以下の画像みたいに撮影したオブジェクトだけがセグメントとして表示すると思います。
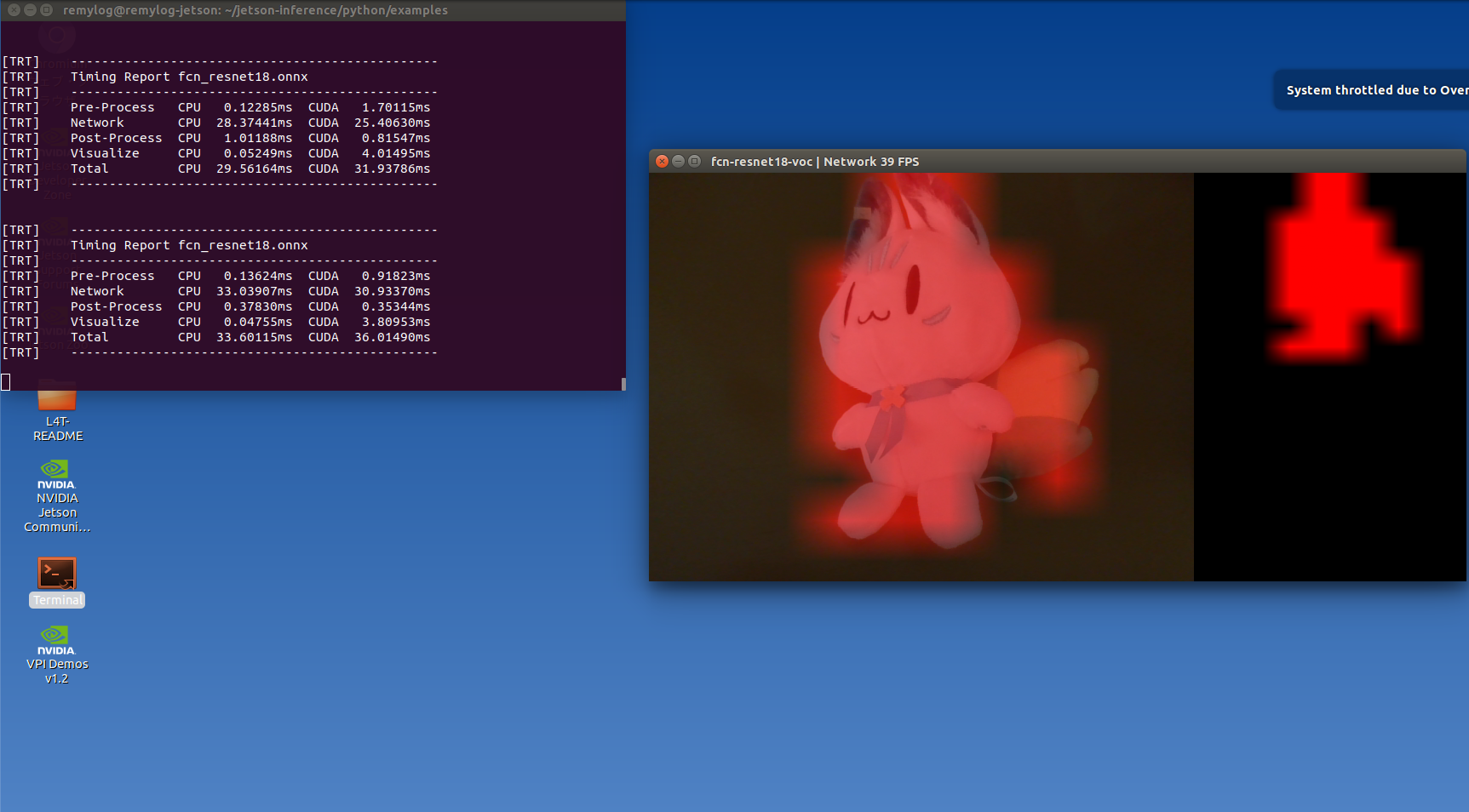
まとめ
今回はセグメンテーションをJetson Nano でする方法を紹介しました。ディレクトリの位置が複雑なので少し難しいと思いますが頑張ってチャレンジしてみてください。


コメント